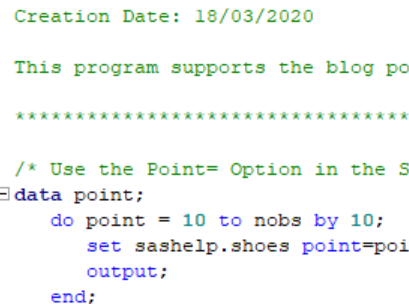
Extract Every N’th Observation From a SAS Data Set
This post demonstrates how to select every nth observation from a SAS data set using the Point= Option, the Mod Function in the Data Step or PROC SQL.
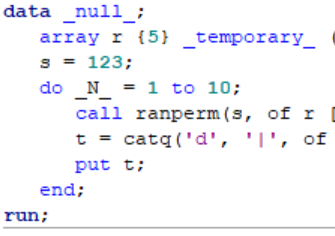
SAS Data Step Permutations with Randperm and Allperm
This post demonstrates how to generate permutations in the SAS Data Step with the Call Randperm and Call Allperm Routines.
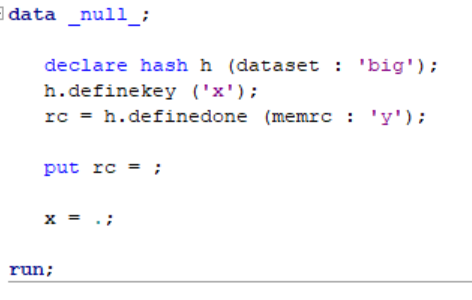
The Hash Object Memrc Option in Definedone
This post investigates the Memrc Argument to the Definedone Method in the SAS Hash Object. Not all the points are clear from the documentation.
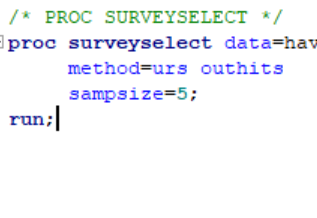
Random Sampling in SAS With Replacement
Here, I demonstrate how to do random sampling with replacement in SAS with the Data Step and PROC SURVEYSELECT. Also, I discuss when to use which one.
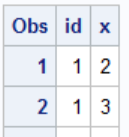
Random Sampling in SAS Without Replacement
Random sampling lets you select a random subset of observations from a data set. Statisticians use random sampling to draw inferences about populations based on subsets of that population. The subject of random sampling is massive. There are many different techniques...
My 10 All Time Favourite SAS Articles
I like to read SAS articles. In fact, articles inspire many of the posts on my blog. Today, I will show you the 10 articles that taught me the most. This was not an easy task. There are so many great articles. In so many fields within SAS. By so many great authors....
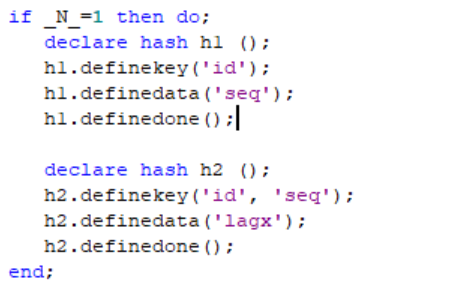
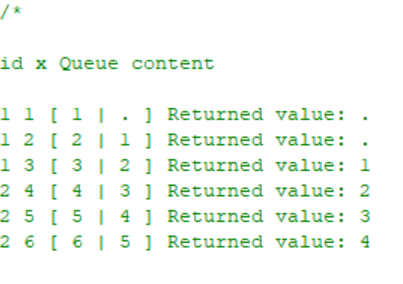
Dynamic Lags in SAS with the Hash Object
This post demonstrates how to use the SAS Hash Object to create dynamics lags. Also, we will see how this method handles By Groups swiftly.
Investigating the SAS Lag Function By Example
The SAS Lag Function can produce undesirable results if not used with care. This post explains through example how the Lag Function works.
SAS Function Vs Subroutine in PROC FCMP
This post demonstrates the difference between a SAS function and a subroutine in PROC FCMP. Also, we will investigate when to use which.
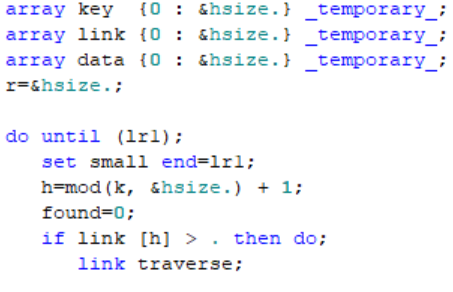
An Array Hashing Scheme in SAS
This post demonstrates how to implement a hashing lookup scheme in SAS using temporary arrays and the MOD Function in the Data Step.