In the SAS Community, there is often confusion about the Nodupkey and the Nodup Options in PROC SORT. Though the options have similar names, their functionality is widely different. This page demonstrates the difference between the two by example.
The two options are best demonstrated with a small example data set like this.
data MyData; input ID var; datalines; 1 10 1 20 1 10 2 30 2 30 2 40 3 50 3 50 3 50 ; |
Nodupkey
 I have previously written about using the Nodupkey Option in the example page Remove Duplicates in SAS. When we examine the PROC SORT Documentation for the Nodupkey Option, we can see that: “The Nodupkey Option checks for and eliminates observations with duplicate BY values”. This means that the Sort Procedure considers only the variables in the By Statement and deletes any duplicate values.
I have previously written about using the Nodupkey Option in the example page Remove Duplicates in SAS. When we examine the PROC SORT Documentation for the Nodupkey Option, we can see that: “The Nodupkey Option checks for and eliminates observations with duplicate BY values”. This means that the Sort Procedure considers only the variables in the By Statement and deletes any duplicate values.
You can use the Dupout= Option to output the deleted observation for later analysis. Furthermore, be aware that the Nodupkey Option has the opposite: The Nouniquekey Option. You can read about it in the blog post Three Other PROC SORT Options you Should Know.
A natural question that arises is what observation does the Nodupkey Option preserve? The answer depends on other factors than just the data and the option itself. See the article Does NODUPKEY Select the First Record in a By Group? for a comprehensive discussion.
proc sort data=MyData nodupkey; by ID; run; |
Nodup
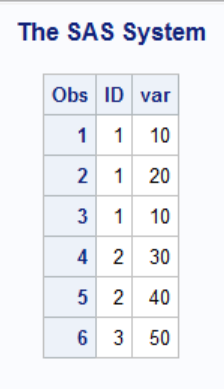 Though the Nodup also deals with duplicate observations, it does so in a different manner than the Nodupkey. While the Nodupkey considers only variabels in the By Statement, the Nodup Option considers entire observations. When Nodup is specified, the Sort Procedure compares the current observation to the previous observation. If the observations matches for all variables, the current observation is left out of the output data set.
Though the Nodup also deals with duplicate observations, it does so in a different manner than the Nodupkey. While the Nodupkey considers only variabels in the By Statement, the Nodup Option considers entire observations. When Nodup is specified, the Sort Procedure compares the current observation to the previous observation. If the observations matches for all variables, the current observation is left out of the output data set.
The Nodup Option is best demonstrated with an example. Consider the example SAS data set at the top of the post. The data contains three by-groups for ID=1, 2 and 3. Let us look at them separately.
- ID=1: The ID=1 group has no observations that follow each other and are an exact match. Observation 1 and 3 matches exactly. However, they do not immediately follow each other. Therefore all observations in the group are written to the new data set.
- ID=2: The two first observations in the ID=2 group are an exact match. Consequently, when PROC SORT considers the second observation, it concludes that it matches the preceding observation exactly and leaves it out. The third observation is naturally written to the new data set.
- ID=3: All three observations in the ID=3 by group matches exactly. Not surprisingly, only the first observation is written to the new data set.
I like to use Noduprec, which is simply a synonym for Nodup, because it is more obvious that it is not the Nodupkey Option.
proc sort data=MyData noduprec; by ID; run; |
Summary
In this post, we have examined the two PROC SORT Options Nodupkey and Nodup (Noduprec). It is quite common among programmers to confuse the two options with each other. This can be dangerous because they yield very different results. Always examine the documentation thoroughly before using an option in SAS you are not entirely familiar with.
I present a PROC SORT alternative to remove duplicate observations in the blog post Remove Duplicate Observations In SAS with the Hash Object.
You can download the entire code from this post here.