Most SAS programmers know about the Set Statement and the Merge Statement in the Data Step. Fewer know about the Update Statement. It is not as common as the two. However, it can be a quite handy tool under the right circumstances. This post demonstrates how to use the Update Statement by example.
An Introductory Example
 The SAS Update Statement updates a Master data set with Transactions from a Transaction data set. The Update Statement is best explained by an example. In the code below, I create A Master and a Transaction data set to demonstrate. Both data sets are sorted by ID. This is a requirement for the input data sets in the Update Statement.
The SAS Update Statement updates a Master data set with Transactions from a Transaction data set. The Update Statement is best explained by an example. In the code below, I create A Master and a Transaction data set to demonstrate. Both data sets are sorted by ID. This is a requirement for the input data sets in the Update Statement.
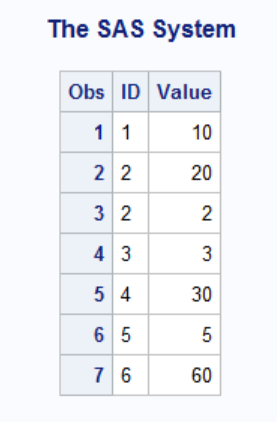
Now, the execution proceeds as follows. SAS reads in the first observation from the Update Statement into the PDV. Next, SAS applies all the transactions for the relevant ID to the observation. That means, that if multiple observations exists for the same ID in the transaction data set, only the last observation will be updated to the output data set in the end. If multiple observations exist for the same ID in the Master data set, SAS ignores these. Consequently, SAS updates only the first observation for each By-Group. Take a look at the result to the right. Notice that for ID=2, SAS only updates the first observation.
An important feature of the Update Statement is how it deals with missing values. In the code below, I specify Updatemode=Missingcheck. This means that missing values in the Transaction data set do not overwrite values in the Master data set. You can change this behavior with Updatemode=Nomissingcheck. Again, look at the results to the right. For ID=5, Value=5 in the Master data set. Even though an observation exists for ID=5 in the Transaction data set, SAS does not overwrite because it is a missing value.
Finally, notice that an observation for ID=6 exists in the Transaction data set. However, it does not in the Master data set. As a consequence, SAS appends a new observation to the output data set.
data Master; input ID $ Value; datalines; 1 1 2 2 2 2 3 3 4 4 5 5 ; data Trans; input ID $ Value; datalines; 1 10 2 20 4 10 4 20 4 30 5 . 6 60 ; data want; update Master Trans updatemode=missingcheck; by ID; run; |
Update Vs Merge Statement
It is easy to confuse the Update to the Merge in the Data Step. However, they differ in fundamental ways. Run the code below and check the outcome. This data set contains 9 observations. The data set from above contains only 7 observations. Below, I will explain how the two statements process data differently.
data MergeWant; merge Master Trans; by ID; run; |
First and foremost, the Update Statement deals with exactly two data sets. On the other hand, the Merge can handle as much as 256 data sets. Also, a By Statement must follow the Update Statement immediately. That is not the case with the Merge Statement.
Besides the two differences above, there are two fundamental differences in the way the the two statements processes data. Namely how they process multiple observations in by groups. And how they deal with missing values.
As you have seen, the MergeWant data set contains two observations more than the Wand data set. This is due to the way that the two statements process multiple observations in the same By-Group. With an Update, SAS does not write an updated observation to the new data set until it has applied all the transactions in a BY group. However, with the Merge Statement, SAS outputs as many observations for each By-Group as the number of observations in the By-Group with the highest number of observations. Consequently, MergeWant contains 3 observations for ID=4. While Want contains only 1.
Furthermore, the Update Statement does not overwrite observations with missing values by default. However, the Merge does. That is why for ID=5, the value is missing in MergeWant. But not in the previous Want data set.
A Practical Application
I have previously written about a quite handy trick with the Update Statement in the blog post Replace Missing Values with Previous Observations. I will not go into details with it here. Rather leave it as an example of how the Update Statement provides a functionality, that no other statement does.
/* Replace missing values with previous */ data MyData; input ID $ Value; datalines; 1 2 1 . 1 . 1 4 2 . 2 9 2 . 2 . 3 3 3 . 3 0 ; data Want; update MyData(obs=0) MyData; by ID; output; run; |
Summary
In this post, I demonstrate the Update Statement in the SAS Data Step by example. I discuss how it differs from the well known Merge Statement. Furthermore, I provide a practical application from a previous post.
For more information about the Update Statement, consult the SAS Update Statement Documentation. Also, if you want to understand exactly what happens in the PDV during execution of an Update Statement, see the article Updating a Data Set from the documentation. In a future post, I will write about Using the Modify Statement in SAS. Also, see the related post When Does the SAS Data Step Set Variable to Missing?
You can download the entire code from this post here.